
Patient Matching in Healthcare: Why Identity Resolution Is the Hardest Problem in NHS Data
Why patient matching in healthcare is harder than NHS Trusts assume, where identity resolution actually breaks, and the integration pattern that holds up.Patient matching is one of those problems that nobody wants to own. The clinicians assume the IT team has it covered. The IT team assumes the PAS has it covered. The PAS assumes PDS has it covered. The data quality team has a spreadsheet of potential duplicates that has been growing for two years, and nobody has authority to press the merge button.
This is the quiet centre of patient matching in healthcare. Not the algorithm, not the standard, not the API. The fact that identity resolution sits between four teams and three systems, with consequences that are clinical, financial, and reputational, and that the cost of getting it wrong only becomes visible after the wrong record has already been written to.
This piece is for the integration architect, IG lead, or Digital Programme Manager who keeps getting pulled into duplicate-record conversations and wants the underlying picture, not just a one-off fix.
The reconciliation queue that never empties
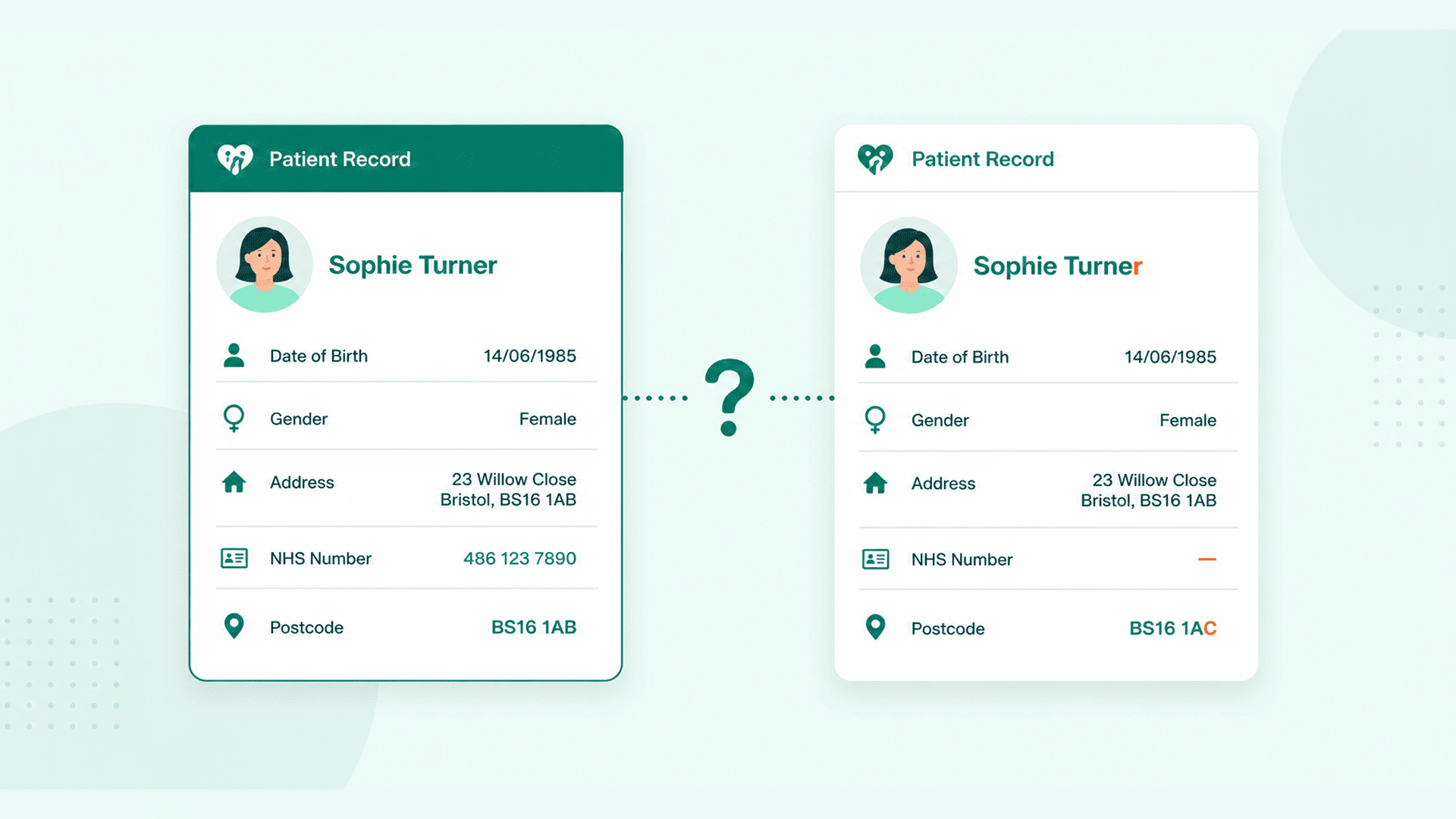
You have probably seen this queue. A list of suspected duplicate patient records, ranked by some internal score, sitting in a tool that the data quality team logs into twice a week. Each row is two patient records that the system thinks might be the same person. Some are obvious matches. Some are obvious non-matches. The middle band — the ones that need a human to look at the notes and decide — is the band that never shrinks.
Behind each of those rows is a real operational moment. A patient arrived at A&E without identification and was registered with a temporary MRN. Three days later a PDS trace returned a probable match against a record from another Trust. A baby was registered locally on the day of birth, then issued an NHS Number via NN4B two days later. A cross-Trust referral landed with a demographic snapshot that disagreed with what the receiving PAS already held for that patient.
None of these are unusual. They are the daily texture of NHS data. And every one of them is a patient matching decision that has to be resolved somewhere, by some logic, with some level of human oversight. The Trusts that have the cleanest data aren't the ones with the fewest of these events. They are the ones who have built identity resolution as a continuous process rather than a one-off cleanup.
Why the NHS Number isn't the answer (even though it's the answer)
The official answer to patient matching in the NHS is the NHS Number. Verified, traced via PDS, treated as the single national identifier for the patient. In a clean world, that is the answer.
The clean world isn't where most integrations run.
NHS Numbers are missing or wrong on a non-trivial slice of records, particularly in unscheduled care, neonates, overseas visitors, and any cohort where the patient arrived before identity could be verified. Local systems hold a mix of MRN, NHS Number, and a cached PDS demographic that may have drifted since the last trace. Cross-Trust care introduces additional identifiers. Sensitive flags constrain what can be matched at all. And the PDS trace itself is not a lookup — it's a multi-step process that returns confidence levels and sometimes multiple candidates.
So when an architect says "we use the NHS Number", the honest follow-up is: which NHS Number, traced against PDS at what point in time, with what fallback when it's absent, and what happens when the demographic data in your system disagrees with the demographic data PDS returned? Those four questions are where patient matching actually lives. Everything else is housekeeping.
What patient matching actually involves
Stripped of the marketing language, patient matching in healthcare is the problem of deciding whether two records describe the same person, when both records are imperfect, the consequence of a wrong answer is clinical, and the rules for "imperfect" change depending on the population.
That involves at least four distinct activities, and most Trusts only have a process for two of them:
- Verification. Confirming that a presented NHS Number actually belongs to the person in front of you, by tracing against PDS and comparing demographics. Most Trusts do this reasonably well at registration.
- Resolution. Deciding which existing record to associate a new event with, when the event arrives without a fully verified identifier. This is where ED, maternity, and inbound referrals run into trouble.
- Reconciliation. Continuously checking the local record against the national source of truth, because demographics drift, sensitive flags get added, and previously unmatched records gain NHS Numbers over time.
- Merging. The irreversible decision to consolidate two records that have been confirmed as the same person. This is the step most Trusts treat as a manual exception process, which is why duplicate queues grow.
Treating these as one problem is the source of most patient matching failures. They have different latency requirements, different confidence thresholds, and different audit obligations. A single matching service that doesn't separate them will be wrong in different ways for different use cases, and the wrongness will be hard to debug because the failure mode looks identical from the outside.
Six places identity resolution breaks in practice
The break points are predictable once you've seen a few Trusts:
1. The walk-in registration.A patient arrives at ED without ID. A temporary MRN is created. The PDS trace runs asynchronously and returns a probable match an hour later. Whether that match is automatically applied, queued for review, or ignored depends on local configuration that the original implementer no longer works at the Trust to explain.
2. The newborn record.NN4B issues an NHS Number after the local system has already created a record. If the integration doesn't have a defined workflow for retroactively associating the NHS Number, you have two records for one baby from day one.
3. The demographic drift.A patient moves house. Their GP updates PDS. Your local system, last traced eighteen months ago, still holds the old address. Every demographic-based match attempt now scores lower than it should. Some legitimate matches fall below the confidence threshold and never surface.
4. The cross-Trust referral.An inbound e-RS referral or a SCR pull lands with a demographic snapshot. The receiving PAS doesn't find an exact match and creates a new record. Now the same patient has two MRNs — one at each Trust — and any future integration between the two systems will treat them as different people.
5. The sensitive flag.S-flagged records cannot be matched, displayed, or reconciled through normal channels. If your matching service doesn't handle this explicitly, you'll either expose data that should be restricted or you'll silently exclude records from reconciliation and never know it.
6. The cached PDS response.Caching PDS responses reduces latency and load, both of which matter. Caching without an invalidation strategy means you're matching against a snapshot that may already be wrong. The right TTL depends on the use case, which means there isn't a single right answer, which means most integrations pick one and forget.
Deterministic, probabilistic, and the part everyone skips
Patient matching algorithms broadly fall into two camps. Deterministic matching uses exact rules — NHS Number plus DOB, or surname plus DOB plus postcode. Probabilistic matching scores the likelihood that two records describe the same person, based on weighted field comparisons that handle typos, transpositions, and partial matches.
The mature view is that you need both. Deterministic matching is fast, auditable, and right when the identifiers are clean. Probabilistic matching catches the cases deterministic misses, which is where most of the duplicate queue comes from. Trusts that only do deterministic matching have low false positives and high false negatives. Trusts that lean too hard on probabilistic matching without a confidence band have the opposite problem.
The part most implementations skip is confidence-banded handling. A high-confidence match writes through automatically. A medium-confidence match goes to a human review queue with the matched fields surfaced. A low-confidence match is treated as a non-match and logged. That three-tier model is the single biggest improvement most Trusts can make to their patient matching pipeline, and it doesn't require buying anything new. It requires deciding what thresholds you trust, documenting them, and routing accordingly.

What good looks like, an identity service, not a field
The Trusts that have stopped fighting the duplicate queue tend to share four properties in their architecture.
They treat identity as a service, not a field on a payload. Every integration that needs to identify a patient calls the identity service, which handles PDS tracing, demographic matching, confidence scoring, and audit. The local PAS isn't doing this work in eight different ways across eight different integrations.
They run continuous reconciliation, not point-in-time matching. A scheduled workflow re-traces local records against PDS, surfaces drift, and queues changes for review where the confidence is mixed. Records aren't matched once and forgotten.
They log every match decision at the field level. What was the input, which fields agreed, which disagreed, what confidence band did the match fall into, what was done with it. This is the audit trail that makes IG and DSPT conversations short instead of painful, and it's what lets the team debug a wrong match six months later without guessing.
They build the merge step as a governed workflow, not a button. Confirmed duplicates flow into a review process with the right roles, the right notes, and a reversal path where possible. The merge isn't pushed onto a single overworked person on a Friday afternoon.
This is the pattern any serious patient matching implementation will converge on. The technology choice matters less than the discipline of treating identity as a first-class concern rather than a side effect of registration.
The bottom line
Patient matching in healthcare isn't going to be solved by a better algorithm. It's an architecture problem, and the architecture decision is whether your Trust treats identity as a service or as a field. Until that decision is made deliberately, the duplicate queue will keep growing, the reconciliation work will keep falling on the data quality team, and the clinical risk of a wrong match will sit unaddressed in the background.
If the queue at the top of this article exists in your Trust, the next step isn't to procure a new tool. It's to map every system that currently performs identity logic, count how many different ways the same decision is being made, and decide where the canonical service should live. That single piece of work is worth more than any matching algorithm you could buy on top of the current mess.
If you're working through that mapping and want a second pair of eyes, WeHub's integration team has done it across enough Trusts that the patterns are familiar.
Keywords
Ready to fix this in your workflow stack?
Related Blogs
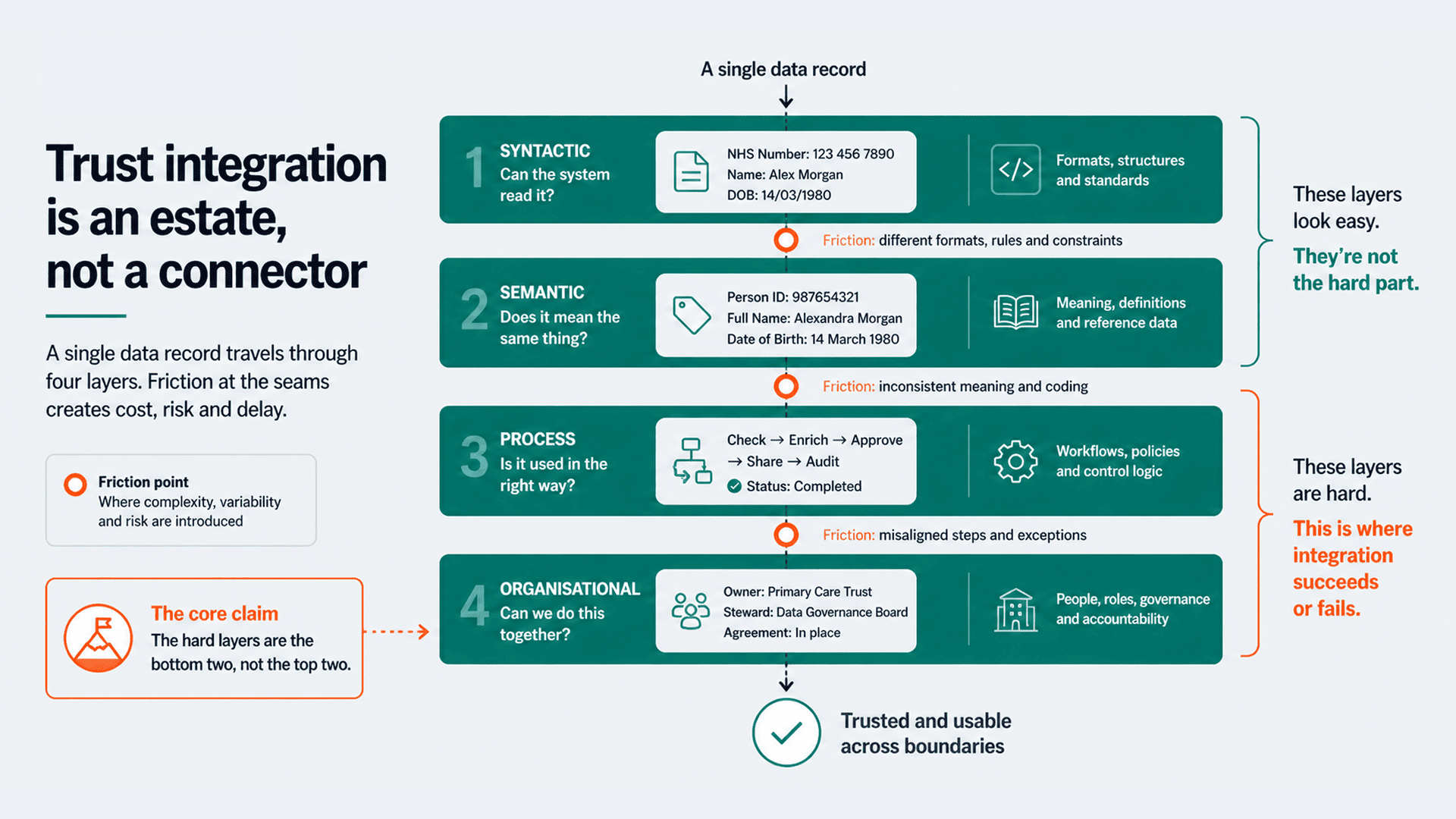
Turn healthcare workflow ideas into production-ready delivery
Whether you're exploring interoperability, workflow automation, HL7, FHIR, ESR, or internal operational delivery, WeHub helps teams design, govern, and run workflows without unnecessary complexity.
- Built for healthcare integration and operations
- Faster delivery with reusable workflow components
- Better governance, visibility, and scale