
Why NHS Clinical Workflows Break at the Handoff, and What Event-Driven Automation Fixes
Most NHS clinical workflows still wait on a clock: a batch job, a nightly file, a polling interval. Event-driven automation in healthcare flips that, letting systems react the moment something actually happens, and it changes more than just speed.
A referral comes into a Trust at 16:42. The clinical system records it. The integration that moves it onward to the receiving service runs as a scheduled job at 02:00. So a referral that was clinically actionable before the end of the working day doesn't reach the team that needs to triage it until the early hours, and isn't looked at by a human until the next morning. Nobody made a mistake. The data was correct. The integration ran exactly as designed. The delay was built into the architecture.
That gap between something happening and a system responding to it is where a surprising amount of clinical risk and operational friction lives. Event driven automation in healthcare is the shift away from time-based integration, where systems act on a schedule, towards event-based integration, where systems act the moment a meaningful thing occurs. It sounds like a technical distinction. In practice it changes how fast care moves, how much manual chasing teams do, and how visible problems are when they happen.
This piece is for the IT Lead, Digital Lead, or integration architect who keeps hearing the phrase "event-driven" in vendor decks and wants to know what it actually means for clinical workflows, where it genuinely helps, and where it's just a rebranded version of what you already have.
The referral that sat in a queue for nine hours
The referral above isn't unusual. Most Trust integrations are built around scheduled file transfers and polling. A system asks, on a timer, "is there anything new?" and acts on whatever it finds. It's reliable, it's predictable, and for a lot of back-office work it's completely fine.
The problem starts when the work is clinical and the timer is slower than the need. An ADT feed that batches admissions hourly means the bed management view is up to an hour out of date. A discharge summary that flows to the GP on a nightly job means the GP can be seeing a patient before the record of yesterday's discharge has arrived. A pathology result that triggers a downstream action only when a polling job next runs means the action waits for the poll, not for the result.
None of these are dramatic failures. That's exactly why they persist. The totals reconcile, the audit looks clean, the job ran. The cost is hidden in the lag: the chasing, the duplicate phone calls, the "has that come through yet?" messages, and occasionally the clinical decision made on information that was technically available but hadn't moved yet.

What event-driven automation actually means in a clinical setting
Strip away the vendor language and the idea is simple. Instead of a system periodically asking whether anything has changed, the system that owns the change announces it the moment it happens, and anything that cares about that change reacts immediately.
In NHS terms, the events are the things clinicians and operational teams already think in: a patient is admitted, a referral is accepted, a result is verified, a prescription is issued, a record is updated on PDS. Each of those is an event. Event-driven automation means treating those moments as the trigger, rather than waiting for a clock to come round and notice them.
The mechanics matter less than the mental model. Whether it's delivered through HL7 v2 messaging, FHIR subscriptions, a message broker, or a workflow engine listening for changes, the defining property is the same: the workflow starts because something happened, not because a timer fired. That single shift is what people are gesturing at when they say "event-driven", and it's worth being precise about, because plenty of systems described that way are still polling underneath.
Why batch and polling quietly fail clinical work
Batch and polling are not bad engineering. They fail clinical workflows for specific, predictable reasons, and naming them helps you spot where event-driven design earns its place and where it doesn't.
1. Latency is built in, not accidental. A nightly job has a worst-case delay of nearly 24 hours by design. For payroll that's fine. For a discharge summary or a deteriorating-patient alert, the delay is the risk.2. The system reacts to the clock, not the clinical reality. A polling interval treats a routine update and an urgent result identically, because it only knows "time has passed", not "something important happened".3. Failures hide between runs. When a batch partially fails, the gap often isn't visible until the next run, or until a human notices something missing. Event-driven flows tend to surface a failure at the moment of the event, which is when someone can still act on it.4. Manual chasing fills the gap. Where the integration is slow, humans compensate. The ward phones the lab. The GP practice phones the Trust. That chasing is invisible in any architecture diagram but very visible in staff time.
The honest counterpoint: not every workflow needs to be event-driven. A monthly workforce report does not benefit from reacting in real time. The skill is knowing which workflows are clock-tolerant and which are not, and most Trusts have historically defaulted everything to the clock because that's how the integration estate grew.
Where event-driven patterns are already showing up in the NHS
This isn't theoretical, and it isn't new. A lot of NHS integration is already event-shaped, even where nobody calls it that.
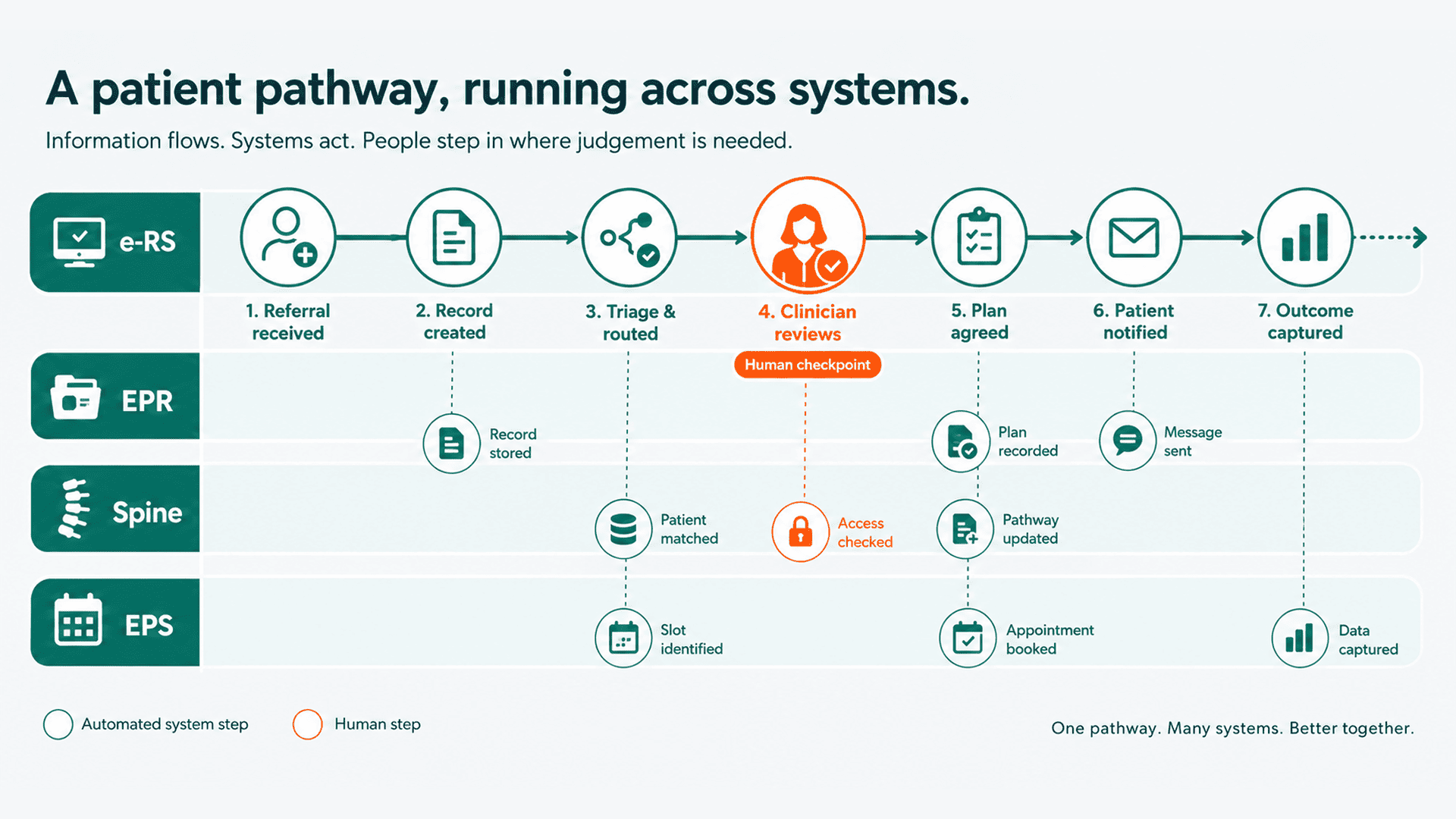
HL7 v2 ADT messaging is event-driven at its core: an admission, transfer, or discharge generates a message at the moment it happens. The pattern has been running in Trusts for decades. FHIR subscriptions extend the same idea to modern APIs, letting a system register interest in a type of change and be notified when it occurs, rather than repeatedly asking. Spine and PDS interactions, e-RS referral state changes, and EPS prescription events all have moments that can act as triggers.
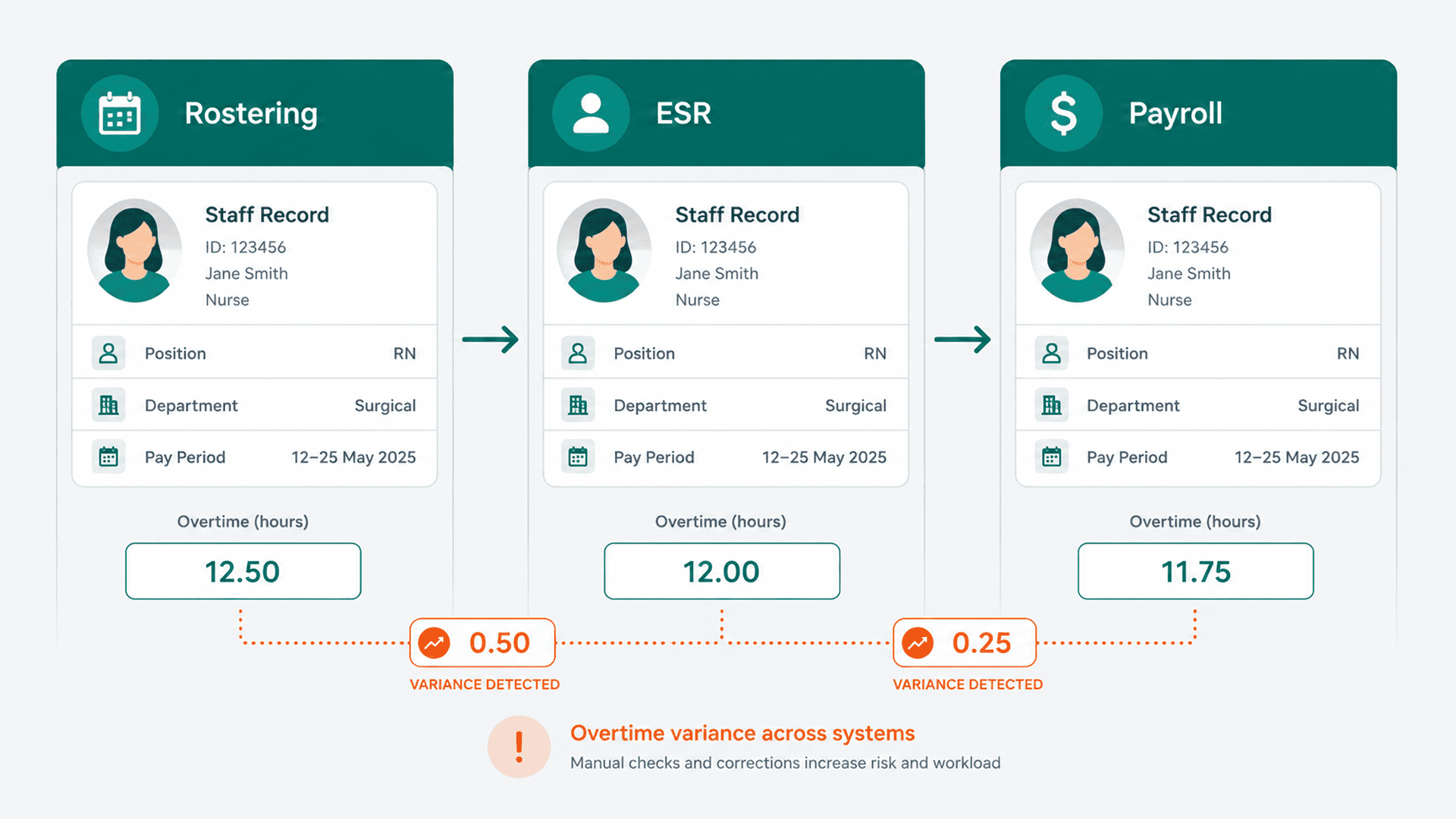
The gap is usually not the source systems. It's the layer in between. A Trust can have ADT messages flowing in real time and still have a downstream workflow that batches them up and processes them on a schedule, reintroducing the very delay the messaging was designed to remove. The event arrives instantly and then sits in a queue waiting for a job. Event-driven automation, done properly, means the reaction is as immediate as the event, all the way through the workflow, not just at the first hop.
What changes when the system reacts to the event, not the clock
When a workflow genuinely becomes event-driven, three things change, and they're worth being concrete about because the benefit is easy to overstate.
The first is speed of response, but only where speed matters. A result that needs acting on triggers the action when it's verified, not when the next poll runs. A referral moves onward when it's accepted, not overnight. The lag that staff used to absorb with phone calls shrinks.
The second is visibility. Because the workflow is tied to discrete events, you can see them: this event arrived, this one was processed, this one failed and here is where. That's a meaningful improvement over a batch job that reports success at the job level while quietly dropping rows. For IG and DSPT conversations, an event-level trail of what happened and when is a far stronger position than "the file ran".
The third is that humans stop being the integration. When the system reacts to the event, the ward clerk, the GP practice administrator, and the coordinator who currently chase missing information by phone are doing that less. The work doesn't disappear, but it moves from chasing to handling exceptions, which is a better use of clinical and administrative time.
What doesn't change: event-driven design doesn't fix bad data, unclear ownership, or a workflow nobody agreed on. If the underlying process is broken, reacting to it faster just breaks faster. The architecture is an amplifier, not a cure.
The questions to ask before you call something event-driven
If you're evaluating a platform or designing a workflow and "event-driven" is on the table, a few questions cut through the marketing quickly.
Does the workflow start from an actual event, or is something still polling underneath and calling the result an event? Does it react to the event end to end, or does it ingest in real time and then batch downstream? When an event fails to process, does that surface at the moment it happens, or at the next run? Is there an event-level audit trail, or only job-level logging? And, crucially, is this a workflow that actually benefits from reacting immediately, or are you adding complexity to something a nightly job handled perfectly well?
Those questions matter more than the underlying technology. A simple message queue used well beats a sophisticated event platform bolted onto a process that didn't need it.
The bottom line
Event-driven automation in healthcare isn't a new category of tool. It's a shift in what triggers the work: the event instead of the clock. For the clinical workflows where delay carries real cost, the referral waiting overnight, the result waiting for a poll, the discharge waiting for a nightly job, that shift takes lag out of care and takes chasing off staff.
If you want a concrete starting point, don't try to re-architect the estate. Pick one workflow where staff are visibly compensating for integration lag, usually the one that generates the most "has that come through yet?" traffic, and map where the delay is actually introduced. More often than not it's not the source system. It's a batch step sitting between two things that could have talked the moment the event happened. That single map tells you whether event-driven design has something to offer you, or whether the clock was fine all along.
Keywords
Ready to fix this in your workflow stack?
Related Blogs

Turn healthcare workflow ideas into production-ready delivery
Whether you're exploring interoperability, workflow automation, HL7, FHIR, ESR, or internal operational delivery, WeHub helps teams design, govern, and run workflows without unnecessary complexity.
- Built for healthcare integration and operations
- Faster delivery with reusable workflow components
- Better governance, visibility, and scale